martes, 26 de noviembre de 2013
Primera visita al blog
Si esta es tu primera visita a este blog recomiendo que visites la página presentación de este blog . Ahí presento el blog, sus propósitos y explico cómo funciona y cómo navegar por él.
Enlaces recomendados:
Listado de artículos
Tipos de análisis
Intervalos óptimos
En ocasiones contamos con una variable métrica que queremos recodificar en una variable ordinal con varias categorías de respuesta. SPSS nos permite crear intervalos a partir de una variable métrica en función de otra variable categórica, nominal u ordinal. Por tanto, lo que hacemos es crear intervalos óptimos para que la variable recodificada ofrezca las mayores diferencias posibles con la variable categoríca seleccionada. Vamos a ver un ejemplo del uso de esta técnica:
Para ello debemos seleccionar en la pestaña transformar, el menú intervalos óptimos. En "variables a agrupar" ponemos la variable métrica que queremos recodificar y en "optimizar invtervalos respecto a" ponemos la variable nominal u ordinal sobre la que queremos encontrar las mejores diferencias.
 Si le damos a aceptar nos aparece la siguente salida. En nuestro caso se han creado cinco intervalos. Si SPSS no encuentra suficiente relación entre las variables no ofrece ninguna salida.
Si le damos a aceptar nos aparece la siguente salida. En nuestro caso se han creado cinco intervalos. Si SPSS no encuentra suficiente relación entre las variables no ofrece ninguna salida.
 Una vez realizada la operación, si el resultado es de nuestro agrado y los intervalos son coherentes, podemos repetir la operación, solo que ahora en la pestaña guardar marcaremos la opción crear variable, que genera automáticamente la nueva variable en función de los rangos optimizados.
Una vez realizada la operación, si el resultado es de nuestro agrado y los intervalos son coherentes, podemos repetir la operación, solo que ahora en la pestaña guardar marcaremos la opción crear variable, que genera automáticamente la nueva variable en función de los rangos optimizados.
 Si le damos a aceptar nos aparece la siguente salida. En nuestro caso se han creado cinco intervalos. Si SPSS no encuentra suficiente relación entre las variables no ofrece ninguna salida.
Si le damos a aceptar nos aparece la siguente salida. En nuestro caso se han creado cinco intervalos. Si SPSS no encuentra suficiente relación entre las variables no ofrece ninguna salida.
 Una vez realizada la operación, si el resultado es de nuestro agrado y los intervalos son coherentes, podemos repetir la operación, solo que ahora en la pestaña guardar marcaremos la opción crear variable, que genera automáticamente la nueva variable en función de los rangos optimizados.
Una vez realizada la operación, si el resultado es de nuestro agrado y los intervalos son coherentes, podemos repetir la operación, solo que ahora en la pestaña guardar marcaremos la opción crear variable, que genera automáticamente la nueva variable en función de los rangos optimizados.
viernes, 22 de noviembre de 2013
Tratamiento valores perdidos
Normalmente cuando hacemos una encuesta hay gente que no sabe o que no quiere responder a determinadas preguntas. También puede ser que no le hayamos hecho dicha pregunta por algún motivo o que en el tratamiento de los datos se haya codificado mal algún caso que distorsione los resultados. Para que estos casos no influyan en el análisis de los resultados es necesario marcar estos casos como perdidos. En esta entrada vamos a ver cómo se realiza dicha tarea:
Una manera de hacerlo es dirigirnos a la vista de variables de SPSS y pinchar en la casilla de perdidos de la variable a modificar. Antes de ello debemos saber los valores que queremos marcar como perdidos. Para ello, si tenemos códigos asignados, los miraremos en la casilla valores de la vista de variables. En caso contrario tendremos que sacar una tabla de frecuencias para ver los valores que componen nuestra variable y estudiar aquellos que queremos considerar como perdidos. En nuestro ejemplo, queremos marcar los valores 8 y 9 como perdidos que son aquellos individuos que no quisieron o que no supieron contestar a la pregunta. Para ello, marcamos dichos valores en el submenú valores discretos.

También es posible definir un rango, por ejemplo podríamos tratar como perdidos todos los casos desde el 7 al 999999 para asegurarnos de que todo valor posible mayor de 7 es tratado como perdido por el sistema. Además se puede marcar el 0 como discreto para asegurarnos de que no se contempla ningún caso que no sea uno de los que tenemos codificados.
En ocasiones debemos realizar el trabajo sobre un grupo de variables, motivo por el cual trabajar una a una deja de ser eficiente. Para estos casos podemos echar mano del comando missing values de la sintaxis de SPSS para designar los valores perdidos por el sistema.
MISSING VALUES
Var1
Var2
Var3
......
(7 to 99999) .
Los valores perdidos dejarán de estar disponibles en los análisis, por ejemplo en las tablas de contingencia o en las tablas personalizadas. Sin embargo, dentro de estas últimas podemos rescatarlos a través de la opción missing del submenú "categoría" de la variable de interés.
Una manera de hacerlo es dirigirnos a la vista de variables de SPSS y pinchar en la casilla de perdidos de la variable a modificar. Antes de ello debemos saber los valores que queremos marcar como perdidos. Para ello, si tenemos códigos asignados, los miraremos en la casilla valores de la vista de variables. En caso contrario tendremos que sacar una tabla de frecuencias para ver los valores que componen nuestra variable y estudiar aquellos que queremos considerar como perdidos. En nuestro ejemplo, queremos marcar los valores 8 y 9 como perdidos que son aquellos individuos que no quisieron o que no supieron contestar a la pregunta. Para ello, marcamos dichos valores en el submenú valores discretos.
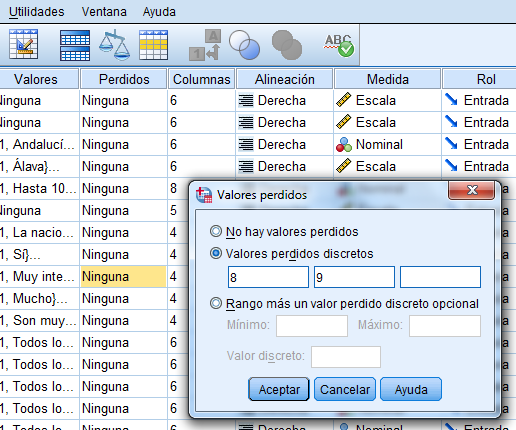
También es posible definir un rango, por ejemplo podríamos tratar como perdidos todos los casos desde el 7 al 999999 para asegurarnos de que todo valor posible mayor de 7 es tratado como perdido por el sistema. Además se puede marcar el 0 como discreto para asegurarnos de que no se contempla ningún caso que no sea uno de los que tenemos codificados.
En ocasiones debemos realizar el trabajo sobre un grupo de variables, motivo por el cual trabajar una a una deja de ser eficiente. Para estos casos podemos echar mano del comando missing values de la sintaxis de SPSS para designar los valores perdidos por el sistema.
MISSING VALUES
Var1
Var2
Var3
......
(7 to 99999) .
Los valores perdidos dejarán de estar disponibles en los análisis, por ejemplo en las tablas de contingencia o en las tablas personalizadas. Sin embargo, dentro de estas últimas podemos rescatarlos a través de la opción missing del submenú "categoría" de la variable de interés.
miércoles, 20 de noviembre de 2013
Cálcular D de Sommers
En esta entrada vamos a ver cómo se calcula la D de Sommers. Su cálculo es parecido a la Gamma y a la Tau-b y c de Kendall .
Al igual que la Tau-b o la Tau-c se calcula teniendo en cuenta el número de casos concordantes, discordantes y empatados resultante del cruce de dos variables. La manera de calcular estos casos ha sido ya explicada en los enlaces arriba citados, por lo que solo resta aplicar la fórmula de la D de Sommers. Hay tres versiones de este estadístico: variable x como dependiente, variable y como dependiente o versión simétrica. Las tres salidas son presentadas por defecto en SPSS. Veamos cómo calcularlas con el siguiente ejemplo:
 Casos concordantes: P= 68.692
Casos discordantes: Q= 35.456
Empatados en x: Tx= 50.360
Empatados en y: Ty= 48.878
Total empatados: T= 99.238
Cálculo D de Sommers para x como dependiente:
Dyx=(P-Q)/(P+Q+Ty)
Dyx= (68.692-35.456)/(68.692+35.456+48.878)= 0,217
Cálculo D de Sommers para y como dependiente:
Dxy=(P-Q)/(P+Q+Tx)
Dxy=(68.692-35.456)/(68.692+35.456+ 50.360)= 0,215
Cálculo D de Sommers simétrica
Dsimetrica= (P-Q)/(P+Q+(T/2))
Dxy=(68.692-35.456)/(68.692+35.456+ 49.619)= 0,216
Casos concordantes: P= 68.692
Casos discordantes: Q= 35.456
Empatados en x: Tx= 50.360
Empatados en y: Ty= 48.878
Total empatados: T= 99.238
Cálculo D de Sommers para x como dependiente:
Dyx=(P-Q)/(P+Q+Ty)
Dyx= (68.692-35.456)/(68.692+35.456+48.878)= 0,217
Cálculo D de Sommers para y como dependiente:
Dxy=(P-Q)/(P+Q+Tx)
Dxy=(68.692-35.456)/(68.692+35.456+ 50.360)= 0,215
Cálculo D de Sommers simétrica
Dsimetrica= (P-Q)/(P+Q+(T/2))
Dxy=(68.692-35.456)/(68.692+35.456+ 49.619)= 0,216
 Casos concordantes: P= 68.692
Casos discordantes: Q= 35.456
Empatados en x: Tx= 50.360
Empatados en y: Ty= 48.878
Total empatados: T= 99.238
Cálculo D de Sommers para x como dependiente:
Dyx=(P-Q)/(P+Q+Ty)
Dyx= (68.692-35.456)/(68.692+35.456+48.878)= 0,217
Cálculo D de Sommers para y como dependiente:
Dxy=(P-Q)/(P+Q+Tx)
Dxy=(68.692-35.456)/(68.692+35.456+ 50.360)= 0,215
Cálculo D de Sommers simétrica
Dsimetrica= (P-Q)/(P+Q+(T/2))
Dxy=(68.692-35.456)/(68.692+35.456+ 49.619)= 0,216
Casos concordantes: P= 68.692
Casos discordantes: Q= 35.456
Empatados en x: Tx= 50.360
Empatados en y: Ty= 48.878
Total empatados: T= 99.238
Cálculo D de Sommers para x como dependiente:
Dyx=(P-Q)/(P+Q+Ty)
Dyx= (68.692-35.456)/(68.692+35.456+48.878)= 0,217
Cálculo D de Sommers para y como dependiente:
Dxy=(P-Q)/(P+Q+Tx)
Dxy=(68.692-35.456)/(68.692+35.456+ 50.360)= 0,215
Cálculo D de Sommers simétrica
Dsimetrica= (P-Q)/(P+Q+(T/2))
Dxy=(68.692-35.456)/(68.692+35.456+ 49.619)= 0,216
Artículos relacionados de este blog:
Artículo principal Tablas de contingencia Cómo calcular Gamma Cómo calcular Tau-b y c de Kendallviernes, 15 de noviembre de 2013
Cálculo de Tau b de Kendall.
Su cálculo es parecido a Gamma pero a diferencia de esta tiene en cuenta los casos empatados. Tiene la ventaja de que en tablas cuadradas (con mismo número de categorías para filas y columnas) puede alcanzar valores entre -1 y 1. En otro tipo de tablas es mejor recurrir a tau-c que puede obtener valores entre -1 y 1 cuando se produce una relación perfecta.
Para calcular la tau b, o la tau c, lo primero que hay que hacer es calcular los casos concordantes, discordantes y empatados. Como en el artículo sobre Gamma v ya hemos visto cómo se calculan los casos concordantes y discordantes vamos a ver cómo se calcularían los casos empatados:
 Los casos empatados serían AB, CD Y EF para la variable x
Los casos empatados para la variable y serían AC, AE, CE, BD, BF, DF
Vamos a ver su cálculo para un ejemplo concreto:
Los casos empatados serían AB, CD Y EF para la variable x
Los casos empatados para la variable y serían AC, AE, CE, BD, BF, DF
Vamos a ver su cálculo para un ejemplo concreto:
 102*50= 5.100
50*30= 1.500
102*30= 3.060
102*56= 5.544
etc... hasta completar la siguiente tabla
102*50= 5.100
50*30= 1.500
102*30= 3.060
102*56= 5.544
etc... hasta completar la siguiente tabla
 Los casos empatados para la "x" son 50.360, mientras que para la "y" son 48,878 Como en el artículo de Gamma ya hemos calculado los casos concordantes y discordantes ya podemos aplicar la fórumla de la tau-b:
Casos concordantes P= 68.692
Casos discordantes Q= 35.456
Los casos empatados para la "x" son 50.360, mientras que para la "y" son 48,878 Como en el artículo de Gamma ya hemos calculado los casos concordantes y discordantes ya podemos aplicar la fórumla de la tau-b:
Casos concordantes P= 68.692
Casos discordantes Q= 35.456
 Dónde "P" son los casos concordantes, "Q" los casos discordantes, "Tx" los casos empatados para la variable x y "Ty" para la variable y.
Aplicando la fórmula nuestra b de kendall sería:
(68.692 - 35.456)/ Raiz ((68692+ 35.456+ 50.360) * (68692+ 35.456+ 48.878)) = 0,216
La tau-b de kendall es igual a 0,216, lo que indica cierta grado de relacción, aunque no muy alto.
Dónde "P" son los casos concordantes, "Q" los casos discordantes, "Tx" los casos empatados para la variable x y "Ty" para la variable y.
Aplicando la fórmula nuestra b de kendall sería:
(68.692 - 35.456)/ Raiz ((68692+ 35.456+ 50.360) * (68692+ 35.456+ 48.878)) = 0,216
La tau-b de kendall es igual a 0,216, lo que indica cierta grado de relacción, aunque no muy alto.
 Los casos empatados serían AB, CD Y EF para la variable x
Los casos empatados para la variable y serían AC, AE, CE, BD, BF, DF
Vamos a ver su cálculo para un ejemplo concreto:
Los casos empatados serían AB, CD Y EF para la variable x
Los casos empatados para la variable y serían AC, AE, CE, BD, BF, DF
Vamos a ver su cálculo para un ejemplo concreto:
 102*50= 5.100
50*30= 1.500
102*30= 3.060
102*56= 5.544
etc... hasta completar la siguiente tabla
102*50= 5.100
50*30= 1.500
102*30= 3.060
102*56= 5.544
etc... hasta completar la siguiente tabla
 Los casos empatados para la "x" son 50.360, mientras que para la "y" son 48,878 Como en el artículo de Gamma ya hemos calculado los casos concordantes y discordantes ya podemos aplicar la fórumla de la tau-b:
Casos concordantes P= 68.692
Casos discordantes Q= 35.456
Los casos empatados para la "x" son 50.360, mientras que para la "y" son 48,878 Como en el artículo de Gamma ya hemos calculado los casos concordantes y discordantes ya podemos aplicar la fórumla de la tau-b:
Casos concordantes P= 68.692
Casos discordantes Q= 35.456
 Dónde "P" son los casos concordantes, "Q" los casos discordantes, "Tx" los casos empatados para la variable x y "Ty" para la variable y.
Aplicando la fórmula nuestra b de kendall sería:
(68.692 - 35.456)/ Raiz ((68692+ 35.456+ 50.360) * (68692+ 35.456+ 48.878)) = 0,216
La tau-b de kendall es igual a 0,216, lo que indica cierta grado de relacción, aunque no muy alto.
Dónde "P" son los casos concordantes, "Q" los casos discordantes, "Tx" los casos empatados para la variable x y "Ty" para la variable y.
Aplicando la fórmula nuestra b de kendall sería:
(68.692 - 35.456)/ Raiz ((68692+ 35.456+ 50.360) * (68692+ 35.456+ 48.878)) = 0,216
La tau-b de kendall es igual a 0,216, lo que indica cierta grado de relacción, aunque no muy alto.
Artículos relacionados
Artículo principal: Tablas de contingencia Gamma Cálculo D de Sommerssábado, 9 de noviembre de 2013
Cálculo de Gamma
Se puede interpretar como la reducción del error cometido al predecir el ordenamiento de los casos de una variable dependiente mediante el conocimiento de la ordenación de una variable independiente.
En este artículo se muestra cómo calcular Gamma. Para conocer qué es Gamma vaya al artículo sobre Tablas de contingencia
Gamma se calcula con la siguiente fórmula:
(C-D)/(C+D)
Dónde C= Casos concordantes y D a casos discordantes
Por tanto, el primer paso para calcular Gamma es calcular el número de casos concordantes y discordantes.
 C= Casos concordantes. Son pares que se encuentran ordenados en el mismo sentido dentro de cada variable. En nuestro ejemplo serían los pares AD; AF; CF que se calcularía cómo A*(D+F) + C*F
D= Casos discordantes. Son casos que se encuentran ordenados en sentido inverso en cada variable. En nuestro ejemplo serían los pares BC; BE; DE que se calcularía cómo B*(C+E)+ D*E
Vamos a ver otro ejemplo de cálculo de casos concordantes y discordantes con dos variables ordinales de tres categorías cada una:
C= Casos concordantes. Son pares que se encuentran ordenados en el mismo sentido dentro de cada variable. En nuestro ejemplo serían los pares AD; AF; CF que se calcularía cómo A*(D+F) + C*F
D= Casos discordantes. Son casos que se encuentran ordenados en sentido inverso en cada variable. En nuestro ejemplo serían los pares BC; BE; DE que se calcularía cómo B*(C+E)+ D*E
Vamos a ver otro ejemplo de cálculo de casos concordantes y discordantes con dos variables ordinales de tres categorías cada una:
 Casos concordantes: 102*(99+88+88+102) + 50*(88+102) + 56*(88+102) 99*102 = 68.692
Casos discordantes: 66*(99+88+50+30) + 88*(88+30) + 56*(50+30)+ 99*30= 35.456
Calculados los casos concordantes y discordantes solo queda aplicar la fórmula de Gamma:
GAMMA= (68.692 - 35.456) / (68.692 + 35.456)= 0,319 En nuestro caso Gamma vale 0,319 lo que indica cierto grado de relación positiva, es decir, conocer el orden de la variable independiente puede ayudarnos a predecir el orden de la variable dependiente.
Como hemos dicho en el artículo sobre tablas de contingencia, Gamma puede inflar la relación existente entre dos variables al no tener en cuenta el número de casos empatados. La tau de kendall es otro estadístico cuyo cálculo es similar al de Gamma pero que además incluye los casos empatados.
Casos concordantes: 102*(99+88+88+102) + 50*(88+102) + 56*(88+102) 99*102 = 68.692
Casos discordantes: 66*(99+88+50+30) + 88*(88+30) + 56*(50+30)+ 99*30= 35.456
Calculados los casos concordantes y discordantes solo queda aplicar la fórmula de Gamma:
GAMMA= (68.692 - 35.456) / (68.692 + 35.456)= 0,319 En nuestro caso Gamma vale 0,319 lo que indica cierto grado de relación positiva, es decir, conocer el orden de la variable independiente puede ayudarnos a predecir el orden de la variable dependiente.
Como hemos dicho en el artículo sobre tablas de contingencia, Gamma puede inflar la relación existente entre dos variables al no tener en cuenta el número de casos empatados. La tau de kendall es otro estadístico cuyo cálculo es similar al de Gamma pero que además incluye los casos empatados.
 C= Casos concordantes. Son pares que se encuentran ordenados en el mismo sentido dentro de cada variable. En nuestro ejemplo serían los pares AD; AF; CF que se calcularía cómo A*(D+F) + C*F
D= Casos discordantes. Son casos que se encuentran ordenados en sentido inverso en cada variable. En nuestro ejemplo serían los pares BC; BE; DE que se calcularía cómo B*(C+E)+ D*E
Vamos a ver otro ejemplo de cálculo de casos concordantes y discordantes con dos variables ordinales de tres categorías cada una:
C= Casos concordantes. Son pares que se encuentran ordenados en el mismo sentido dentro de cada variable. En nuestro ejemplo serían los pares AD; AF; CF que se calcularía cómo A*(D+F) + C*F
D= Casos discordantes. Son casos que se encuentran ordenados en sentido inverso en cada variable. En nuestro ejemplo serían los pares BC; BE; DE que se calcularía cómo B*(C+E)+ D*E
Vamos a ver otro ejemplo de cálculo de casos concordantes y discordantes con dos variables ordinales de tres categorías cada una:
 Casos concordantes: 102*(99+88+88+102) + 50*(88+102) + 56*(88+102) 99*102 = 68.692
Casos discordantes: 66*(99+88+50+30) + 88*(88+30) + 56*(50+30)+ 99*30= 35.456
Calculados los casos concordantes y discordantes solo queda aplicar la fórmula de Gamma:
GAMMA= (68.692 - 35.456) / (68.692 + 35.456)= 0,319 En nuestro caso Gamma vale 0,319 lo que indica cierto grado de relación positiva, es decir, conocer el orden de la variable independiente puede ayudarnos a predecir el orden de la variable dependiente.
Como hemos dicho en el artículo sobre tablas de contingencia, Gamma puede inflar la relación existente entre dos variables al no tener en cuenta el número de casos empatados. La tau de kendall es otro estadístico cuyo cálculo es similar al de Gamma pero que además incluye los casos empatados.
Casos concordantes: 102*(99+88+88+102) + 50*(88+102) + 56*(88+102) 99*102 = 68.692
Casos discordantes: 66*(99+88+50+30) + 88*(88+30) + 56*(50+30)+ 99*30= 35.456
Calculados los casos concordantes y discordantes solo queda aplicar la fórmula de Gamma:
GAMMA= (68.692 - 35.456) / (68.692 + 35.456)= 0,319 En nuestro caso Gamma vale 0,319 lo que indica cierto grado de relación positiva, es decir, conocer el orden de la variable independiente puede ayudarnos a predecir el orden de la variable dependiente.
Como hemos dicho en el artículo sobre tablas de contingencia, Gamma puede inflar la relación existente entre dos variables al no tener en cuenta el número de casos empatados. La tau de kendall es otro estadístico cuyo cálculo es similar al de Gamma pero que además incluye los casos empatados.
Artículos relacionados
Artículo principal: Tablas de contingenciamiércoles, 6 de noviembre de 2013
Cálculo de Chi cuadrado
Como hemos visto en el artículo sobre Tablas de contingencia , la chi cuadrado es un estadístico que avisa de la relación entre dos variables categóricas. Para calcularlo hay que poner en relación las frecuencias esperadas (las que se darían en situación de independencia de las variables) con las frecuencias observadas (las que nos ofrecen nuestros datos. Si nuestras variables están relacionadas entre sí las diferencias entre los valores observados y los esperados serán grandes y la chi será alta. El sumatorio de estas diferencias para cada casilla de nuestra tabla es la chi cuadrado.
Vamos a verlo con un ejemplo:
 El primer paso es calcular las frecuencias absolutas esperadas, que se calculan como el producto de los marginales para cada celda:
E absoluta de celda = marginal de fila por marginal de columna dividido entre número de casos
E hombres y satisfechos = (181 * 201)/ 306 = 119
E mujeres satisfechas = (125 * 201) /306 = 82
E hombres e insatisfechos = (181 * 169)/306= 100
E mujeres e insatisfechas = (125 * 169) /306= 69
El siguiente paso es poner en relación para cada celda las frencuencias esperadas recién calculadas, con las frecuencias observadas en nuestra muestra. Para ello, se aplica el cuadrado de la resta entre el valor observado - el esperado y se divide el resultado por el valor esperado.
[(nij- eij) ^2]/ eij
celda 11. hombres satisfechos= `[(112-119)^2] /119 = 0,412
celda 12. mujeres satisfechas = [(89-82)^2] /82 = 0,598
celda 21. hombres insatisfechos= [(69-100)^2] /100 = 9,61
celda 22. mujeres insatisfechas= [(100-69)^2] /69 = 13,925
Solo queda sumar los cuatro valores obtenidos para hallar la chi cuadrado: (0,412+ 0,598 + 9,61 + 12,925)= 24,547
La chi cuadrado de nuestro ejemplo es de 24,547. Este valor de por sí solo no nos dice nada, por ello, paquetes estadísticos como SPSS nos calcula el coeficiente de significación cuya interpretación se explica en el artículo principal de tablas de contingencia.
Viendo la manera en la que se calcula la chi es fácil entender porque los valores de la chi crecen a medida que aumenta el número de casos. Es por ello que para evitar el efecto del tamaño de la muestra hayan surgido otros estadísticos basados en chi cuadrado que tratan de mitigar los efectos del tamaño muestral, como la la phi, la V de Cramer o el coeficiente de contingencia. Si quiere ver cómo se calculan estos estadísticos vaya al artículo principal sobre tablas de contingencia.
El primer paso es calcular las frecuencias absolutas esperadas, que se calculan como el producto de los marginales para cada celda:
E absoluta de celda = marginal de fila por marginal de columna dividido entre número de casos
E hombres y satisfechos = (181 * 201)/ 306 = 119
E mujeres satisfechas = (125 * 201) /306 = 82
E hombres e insatisfechos = (181 * 169)/306= 100
E mujeres e insatisfechas = (125 * 169) /306= 69
El siguiente paso es poner en relación para cada celda las frencuencias esperadas recién calculadas, con las frecuencias observadas en nuestra muestra. Para ello, se aplica el cuadrado de la resta entre el valor observado - el esperado y se divide el resultado por el valor esperado.
[(nij- eij) ^2]/ eij
celda 11. hombres satisfechos= `[(112-119)^2] /119 = 0,412
celda 12. mujeres satisfechas = [(89-82)^2] /82 = 0,598
celda 21. hombres insatisfechos= [(69-100)^2] /100 = 9,61
celda 22. mujeres insatisfechas= [(100-69)^2] /69 = 13,925
Solo queda sumar los cuatro valores obtenidos para hallar la chi cuadrado: (0,412+ 0,598 + 9,61 + 12,925)= 24,547
La chi cuadrado de nuestro ejemplo es de 24,547. Este valor de por sí solo no nos dice nada, por ello, paquetes estadísticos como SPSS nos calcula el coeficiente de significación cuya interpretación se explica en el artículo principal de tablas de contingencia.
Viendo la manera en la que se calcula la chi es fácil entender porque los valores de la chi crecen a medida que aumenta el número de casos. Es por ello que para evitar el efecto del tamaño de la muestra hayan surgido otros estadísticos basados en chi cuadrado que tratan de mitigar los efectos del tamaño muestral, como la la phi, la V de Cramer o el coeficiente de contingencia. Si quiere ver cómo se calculan estos estadísticos vaya al artículo principal sobre tablas de contingencia.
 El primer paso es calcular las frecuencias absolutas esperadas, que se calculan como el producto de los marginales para cada celda:
E absoluta de celda = marginal de fila por marginal de columna dividido entre número de casos
E hombres y satisfechos = (181 * 201)/ 306 = 119
E mujeres satisfechas = (125 * 201) /306 = 82
E hombres e insatisfechos = (181 * 169)/306= 100
E mujeres e insatisfechas = (125 * 169) /306= 69
El siguiente paso es poner en relación para cada celda las frencuencias esperadas recién calculadas, con las frecuencias observadas en nuestra muestra. Para ello, se aplica el cuadrado de la resta entre el valor observado - el esperado y se divide el resultado por el valor esperado.
[(nij- eij) ^2]/ eij
celda 11. hombres satisfechos= `[(112-119)^2] /119 = 0,412
celda 12. mujeres satisfechas = [(89-82)^2] /82 = 0,598
celda 21. hombres insatisfechos= [(69-100)^2] /100 = 9,61
celda 22. mujeres insatisfechas= [(100-69)^2] /69 = 13,925
Solo queda sumar los cuatro valores obtenidos para hallar la chi cuadrado: (0,412+ 0,598 + 9,61 + 12,925)= 24,547
La chi cuadrado de nuestro ejemplo es de 24,547. Este valor de por sí solo no nos dice nada, por ello, paquetes estadísticos como SPSS nos calcula el coeficiente de significación cuya interpretación se explica en el artículo principal de tablas de contingencia.
Viendo la manera en la que se calcula la chi es fácil entender porque los valores de la chi crecen a medida que aumenta el número de casos. Es por ello que para evitar el efecto del tamaño de la muestra hayan surgido otros estadísticos basados en chi cuadrado que tratan de mitigar los efectos del tamaño muestral, como la la phi, la V de Cramer o el coeficiente de contingencia. Si quiere ver cómo se calculan estos estadísticos vaya al artículo principal sobre tablas de contingencia.
El primer paso es calcular las frecuencias absolutas esperadas, que se calculan como el producto de los marginales para cada celda:
E absoluta de celda = marginal de fila por marginal de columna dividido entre número de casos
E hombres y satisfechos = (181 * 201)/ 306 = 119
E mujeres satisfechas = (125 * 201) /306 = 82
E hombres e insatisfechos = (181 * 169)/306= 100
E mujeres e insatisfechas = (125 * 169) /306= 69
El siguiente paso es poner en relación para cada celda las frencuencias esperadas recién calculadas, con las frecuencias observadas en nuestra muestra. Para ello, se aplica el cuadrado de la resta entre el valor observado - el esperado y se divide el resultado por el valor esperado.
[(nij- eij) ^2]/ eij
celda 11. hombres satisfechos= `[(112-119)^2] /119 = 0,412
celda 12. mujeres satisfechas = [(89-82)^2] /82 = 0,598
celda 21. hombres insatisfechos= [(69-100)^2] /100 = 9,61
celda 22. mujeres insatisfechas= [(100-69)^2] /69 = 13,925
Solo queda sumar los cuatro valores obtenidos para hallar la chi cuadrado: (0,412+ 0,598 + 9,61 + 12,925)= 24,547
La chi cuadrado de nuestro ejemplo es de 24,547. Este valor de por sí solo no nos dice nada, por ello, paquetes estadísticos como SPSS nos calcula el coeficiente de significación cuya interpretación se explica en el artículo principal de tablas de contingencia.
Viendo la manera en la que se calcula la chi es fácil entender porque los valores de la chi crecen a medida que aumenta el número de casos. Es por ello que para evitar el efecto del tamaño de la muestra hayan surgido otros estadísticos basados en chi cuadrado que tratan de mitigar los efectos del tamaño muestral, como la la phi, la V de Cramer o el coeficiente de contingencia. Si quiere ver cómo se calculan estos estadísticos vaya al artículo principal sobre tablas de contingencia.
Artículos relacionados:
Artículo principal: Tablas de contingencia
Cálculo Tau de Goodman
Como hemos dicho en la entrada sobre Tablas de contingencia , la Tau de Goodman es un estadístico utilizado para medir la fuerza de la relación entre dos variables nominales. Al igual que lambda
o el Coeficiente de incertidumbre es un estadístico basado en el error, por lo que el primer paso es calcular dichos errores. Su cálculo es similar al de Lambda, aunque es algo más complejo. Al contrario que Lambda toma en consideración para calcular el error todas las categorías de respuesta y no únicamente la que más casos tiene, por lo que el cálculo de los errores es algo más complejo. Para calcular la Tau hay que calcular primero los errores que se cometen al asignar aleatoriamente los casos para la variable dependiente.
Veamos cómo se calculan los errores con el siguiente ejemplo:

Cálculo Error tipo 1 o error no condicionado. Es el error que se produce al estimar el valor de un caso en la variable dependiente, sin tener en cuenta la información procedente de la variable independiente. ∑_i^k▒〖(n-fi)/n x fi〗 Donde ”k” es el número de casos de la variable dependiente. “n” el número total de casos y “fi” la frecuencia de la categoría i: Error categoría satisfechos = [(540-215)/540] *215 = 129,4 Error categoría ni satis/ni insatis= = [(540-145)/540] *145 = 106,06 Error de la Categoría insatisfecho = = [(540-180)/540] *180 = 355,46 Total de errores tipo 1 = 129,4 + 106,06 + 344,46= 355,46
Cálculo de error de tipo 2 o condicionado:
El cálculo de este error procede de la misma manera pero su cálculo no se realiza para los marginales de columna, sino que se calcula por separado para cada una de las categorías de la variable independiente, columnas 1 y2. E2=∑^C▒∑_(i=1)^K▒(Ni-n)/Ni x ni Donde ni es la frecuencia de cada celda de la variable dependiente dentro de cada celda de la variable independiente. Ni es el total de casos de cada categoría de la independiente. Error hombres satisfechos= [(266-114)/266] *114 = 65,14 Error hombres ni-ni= [(266-60)/266] *60 = 46,47 Error hombres insatisfechos = [(266-92)/266] * 92= 60,18 Error mujeres satisfechas = [(274-101)/274] *101 = 63,77 Error mujeres ni-ni = [(274-85)/274] *85 = 58,63 Error mujeres insatisfechas = [(274-88)/274] *88 = 59,74 Error tipo 2 = (65,14 + 46,47+ 60,18+ 63,77+ 58,63 + 59,74) = 353,93

Cálculo Error tipo 1 o error no condicionado. Es el error que se produce al estimar el valor de un caso en la variable dependiente, sin tener en cuenta la información procedente de la variable independiente. ∑_i^k▒〖(n-fi)/n x fi〗 Donde ”k” es el número de casos de la variable dependiente. “n” el número total de casos y “fi” la frecuencia de la categoría i: Error categoría satisfechos = [(540-215)/540] *215 = 129,4 Error categoría ni satis/ni insatis= = [(540-145)/540] *145 = 106,06 Error de la Categoría insatisfecho = = [(540-180)/540] *180 = 355,46 Total de errores tipo 1 = 129,4 + 106,06 + 344,46= 355,46
Cálculo de error de tipo 2 o condicionado:
El cálculo de este error procede de la misma manera pero su cálculo no se realiza para los marginales de columna, sino que se calcula por separado para cada una de las categorías de la variable independiente, columnas 1 y2. E2=∑^C▒∑_(i=1)^K▒(Ni-n)/Ni x ni Donde ni es la frecuencia de cada celda de la variable dependiente dentro de cada celda de la variable independiente. Ni es el total de casos de cada categoría de la independiente. Error hombres satisfechos= [(266-114)/266] *114 = 65,14 Error hombres ni-ni= [(266-60)/266] *60 = 46,47 Error hombres insatisfechos = [(266-92)/266] * 92= 60,18 Error mujeres satisfechas = [(274-101)/274] *101 = 63,77 Error mujeres ni-ni = [(274-85)/274] *85 = 58,63 Error mujeres insatisfechas = [(274-88)/274] *88 = 59,74 Error tipo 2 = (65,14 + 46,47+ 60,18+ 63,77+ 58,63 + 59,74) = 353,93
Tau= E1 – E2/ E1 = 0,004 Lo que daría una salida en SPSS de 0 indicando que no hay relación entre las variables. O que utilizando los valores de la variable sexo no conseguimos reducir el error al tratar de predecir a que categoría de la variable satisfacción pertenece un caso cualquiera.
Artículos relacionados
Artículo principal: Tablas de contingencia Cálculo de lambda
Cálculo de Lambda
En esta entrada solo se explica como calcular la lambda, estadístico usado en las tablas de contingencia. Si quiere saber más sobre cómo se interpreta y se pide en SPSS vaya al artículo
Tablas de contingencia
λ= (error no condicionado-error condicionado)/(error no condicionado)
Cómo hemos dicho en el artículo sobre
tablas de contingencia
hay tres posibles valores de lambda: simétrico, variable 1 como dependiente y variable 2 como dependiente. Veamos cómo se calcula lambda para un ejemplo concreto en el que usamos el sexo como variable independiente.
 En primer lugar tenemos que calcular los errores: condicionado y no condicionado.
El error no condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente no están condicionadas a otra variable. Por ejemplo, si en nuestro ejemplo quisiéramos estimar la satisfacción de un sujeto cualquiera diríamos que el sujeto está muy insatisfecho, porque es la categoría con mayor número de casos. El error no condicionado sería la suma de las frecuencias del resto de categorías (desde insatisfecho hasta muy satisfecho partido por el número de casos) que sería igual a (49 + 87 + 112 + 126)/500 = 374/500= 0,748. El error no condicionado sería de 0,748, un error muy alto. Calculemos ahora el error condicionado.
El error condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente están condicionadas a los atributos de una variable independiente. Si utilizamos la variable sexo para estimar la satisfacción de un sujeto tendremos un error condicionado a la variable sexo. Veamos cómo calcularlo para nuestros datos.
frec condicionada hombres= 13 + 39 + 52 + 78 + 78 = 182
frec condicionada mujer= 36 + 48 + 48 + 48 = 180
En el caso de los hombres hemos dejado fuera a los muy satisfechos que es la variable con más casos, aunque en este caso tiene el mismo número que la categoría satisfecho. En el grupo de mujeres hemos dejado fuera a los que no están ni satisfechos ni insatisfechos pues son el grupo con más casos.
A continuación se dividen las dos frecuencias obtenidas entre el número total de casos.
182/500= 0,364
180/500= 0,36
Solo queda sumar para obtener el error condicionado: 0,364 + 0,36= 0,724
Calculados el error condicionado y el no condicionado solo resta aplicar la fórmula de lambda.
λ= (0,748 - 0,724)/ 0,748 = 0,024/0,748 = 0,0321
En nuestro ejemplo se reduce el error en 0,0321 al utilizar el sexo como variable independiente, lo cual es una mejoría muy baja.
En primer lugar tenemos que calcular los errores: condicionado y no condicionado.
El error no condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente no están condicionadas a otra variable. Por ejemplo, si en nuestro ejemplo quisiéramos estimar la satisfacción de un sujeto cualquiera diríamos que el sujeto está muy insatisfecho, porque es la categoría con mayor número de casos. El error no condicionado sería la suma de las frecuencias del resto de categorías (desde insatisfecho hasta muy satisfecho partido por el número de casos) que sería igual a (49 + 87 + 112 + 126)/500 = 374/500= 0,748. El error no condicionado sería de 0,748, un error muy alto. Calculemos ahora el error condicionado.
El error condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente están condicionadas a los atributos de una variable independiente. Si utilizamos la variable sexo para estimar la satisfacción de un sujeto tendremos un error condicionado a la variable sexo. Veamos cómo calcularlo para nuestros datos.
frec condicionada hombres= 13 + 39 + 52 + 78 + 78 = 182
frec condicionada mujer= 36 + 48 + 48 + 48 = 180
En el caso de los hombres hemos dejado fuera a los muy satisfechos que es la variable con más casos, aunque en este caso tiene el mismo número que la categoría satisfecho. En el grupo de mujeres hemos dejado fuera a los que no están ni satisfechos ni insatisfechos pues son el grupo con más casos.
A continuación se dividen las dos frecuencias obtenidas entre el número total de casos.
182/500= 0,364
180/500= 0,36
Solo queda sumar para obtener el error condicionado: 0,364 + 0,36= 0,724
Calculados el error condicionado y el no condicionado solo resta aplicar la fórmula de lambda.
λ= (0,748 - 0,724)/ 0,748 = 0,024/0,748 = 0,0321
En nuestro ejemplo se reduce el error en 0,0321 al utilizar el sexo como variable independiente, lo cual es una mejoría muy baja.
 En primer lugar tenemos que calcular los errores: condicionado y no condicionado.
El error no condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente no están condicionadas a otra variable. Por ejemplo, si en nuestro ejemplo quisiéramos estimar la satisfacción de un sujeto cualquiera diríamos que el sujeto está muy insatisfecho, porque es la categoría con mayor número de casos. El error no condicionado sería la suma de las frecuencias del resto de categorías (desde insatisfecho hasta muy satisfecho partido por el número de casos) que sería igual a (49 + 87 + 112 + 126)/500 = 374/500= 0,748. El error no condicionado sería de 0,748, un error muy alto. Calculemos ahora el error condicionado.
El error condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente están condicionadas a los atributos de una variable independiente. Si utilizamos la variable sexo para estimar la satisfacción de un sujeto tendremos un error condicionado a la variable sexo. Veamos cómo calcularlo para nuestros datos.
frec condicionada hombres= 13 + 39 + 52 + 78 + 78 = 182
frec condicionada mujer= 36 + 48 + 48 + 48 = 180
En el caso de los hombres hemos dejado fuera a los muy satisfechos que es la variable con más casos, aunque en este caso tiene el mismo número que la categoría satisfecho. En el grupo de mujeres hemos dejado fuera a los que no están ni satisfechos ni insatisfechos pues son el grupo con más casos.
A continuación se dividen las dos frecuencias obtenidas entre el número total de casos.
182/500= 0,364
180/500= 0,36
Solo queda sumar para obtener el error condicionado: 0,364 + 0,36= 0,724
Calculados el error condicionado y el no condicionado solo resta aplicar la fórmula de lambda.
λ= (0,748 - 0,724)/ 0,748 = 0,024/0,748 = 0,0321
En nuestro ejemplo se reduce el error en 0,0321 al utilizar el sexo como variable independiente, lo cual es una mejoría muy baja.
En primer lugar tenemos que calcular los errores: condicionado y no condicionado.
El error no condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente no están condicionadas a otra variable. Por ejemplo, si en nuestro ejemplo quisiéramos estimar la satisfacción de un sujeto cualquiera diríamos que el sujeto está muy insatisfecho, porque es la categoría con mayor número de casos. El error no condicionado sería la suma de las frecuencias del resto de categorías (desde insatisfecho hasta muy satisfecho partido por el número de casos) que sería igual a (49 + 87 + 112 + 126)/500 = 374/500= 0,748. El error no condicionado sería de 0,748, un error muy alto. Calculemos ahora el error condicionado.
El error condicionado, es el error de predicción cometido cuando las predicciones para los atributos de la variable dependiente están condicionadas a los atributos de una variable independiente. Si utilizamos la variable sexo para estimar la satisfacción de un sujeto tendremos un error condicionado a la variable sexo. Veamos cómo calcularlo para nuestros datos.
frec condicionada hombres= 13 + 39 + 52 + 78 + 78 = 182
frec condicionada mujer= 36 + 48 + 48 + 48 = 180
En el caso de los hombres hemos dejado fuera a los muy satisfechos que es la variable con más casos, aunque en este caso tiene el mismo número que la categoría satisfecho. En el grupo de mujeres hemos dejado fuera a los que no están ni satisfechos ni insatisfechos pues son el grupo con más casos.
A continuación se dividen las dos frecuencias obtenidas entre el número total de casos.
182/500= 0,364
180/500= 0,36
Solo queda sumar para obtener el error condicionado: 0,364 + 0,36= 0,724
Calculados el error condicionado y el no condicionado solo resta aplicar la fórmula de lambda.
λ= (0,748 - 0,724)/ 0,748 = 0,024/0,748 = 0,0321
En nuestro ejemplo se reduce el error en 0,0321 al utilizar el sexo como variable independiente, lo cual es una mejoría muy baja.
Artículos relacionados
Artículo principal: Tablas de contingenciamartes, 5 de noviembre de 2013
Tabla de contingencia
Requisitos
Cómo calcular una tabla de contingencia en SPSS
Interpretación Estadísticos
Ejemplos
Las tablas de contingencia son tablas que ponen en relación los datos de dos variables distintas. A través de un análisis de tabla de contiengencia podremos saber como se relacionan dos variables entre sí. Es uno de los análisis más sencillos y a la vez más utilizados en investigación social y de mercado.
Dos variables categóricas. Si la variable es métrica o interval la tabla de contingencia no sería el análisis adecuado y habria que acudir a otro tipo de análisis o recodificar la variable para convertirla en nominal u ordinal. Al tomar esta decisión perderíamos información en favor de la claridad y sencillez que aporta un análisis de tabla de contingencia.
La ruta a seguir en el SPSS es: Análisis/Estadísticos descriptivos/Tablas de contingencia
Procedimiento: Una variable en la fila y otra variable en la columna. En el menú casilla pedimos el porcentaje por columna, además de la frecuencia de observados que sale en SPSS por defecto. Además, en el menú estadísticos pediremos la chi cuadrado. Con esto tenemos un primer análisis de tabla de contingencia.
Según nuestros datos, generados a partir de dos variables aleatorias, hay 500 personas, 267 hombres y 233 mujeres. 117 personas (un 23,4%) están muy insatisfechas. De ellas, hay 63 hombres, es decir un 23,6% de los hombres, que están muy insatisfechos, mayor porcentaje que entre las mujeres con un 23,2%.

A simple vista no parece que haya mucha diferencia entre la satisfacción de hombres y mujeres, por lo que parece que sexo y satisfacción son variables independientes entre sí. Sin embargo, el ojo de buen cubero no es suficiente y es necesario recurrir a algún tipo de test que sirva para estudiar la dependendica entre las dos variables.
dependencia la hipótesis alternativa.

Al pedir el chi cuadrado SPSS nos da su valor, que se calcula al poner en relación los valores observados con los esperados. En nuestro caso la Chi-cuadrado es de 3,157. Esto de por sí solo no nos dice mucho, sin embargo SPSS también nos facilita el nivel de significación que en este caso es de 0,532. Este nivel indica la probabilidad de rechazar la hipótesis nula de independencia siendo cierta. Si esta probabilidad es menor que 0,05 se rechaza la hipótesis nula y en consecuencia diremos que las variables son dependientes entre sí. En nuestro ejemplo, el nivel de significación es de 0,532, por lo que no podemos rechazar la hipótesis nula y decimos que las variables son independientes entre sí, o que no guardan una relación de dependencia.
Para ver cómo se calcula la chi cuadrado pincha sobre el enlace.
La chi cuadrado está muy influenciada por el tamaño muestral. De modo que cuando tenemos muestras grandes la chi crece y es más fácil rechazar la hipótesis nula de independencia.
Para que el contraste de la chi sea estadísticamente válido cada celda de la tabla deberá tener una frecuencia esperada de 5. En nuestro ejemplo, como se ve en la línea de texto bajo la tabla de ejemplo no hay ninguna casilla que tenga menos de 5, por lo que nuestro test será estadísticamente válido. En el caso de que haya celdas con menos de 5 observaciones una posible solución es la recodificación de una variable con muchas categorías en una con menor número de categorías. Chi cuadrado puede funcionar con un porcentaje pequeño de celdas en las que se espere una frecuencia inferior a 5, pero con más de un 20% de las casillas con una frecuencia menor a 5 el test deja de ser fiable. Hasta ahora solo sabemos si existe o no dependencia entre las variables, pero no sabemos nada acerca del tipo de relación entre las variables . El siguiente grupo de estadísticos sirve para medir el grado de relación entre las variables.

Como se puede observar, los datos de los tres estadísticos coinciden en la tabla de nuestro ejemplo. Phi y Cramer siempre coinciden cuando al menos una de las variables tiene dos categorías de respuesta. El coeficiente de contingencia no es exactamente el mismo, aunque en este caso varía solo en el tercer decimal, que no sale por defecto en SPSS, por lo que coincide con los otros dos estadísticos. Veamos ahora estos estadísticos por separado: -Phi: Permite medir el grado de relación de dos variables. Se utiliza en el caso especial de tablas con dos filas y dos columnas (2x2). Valores cercanos a 0 indican poca relación y valores cercanos a 1 indican mucha fuerza en la relación. Se calcula como la raíz cuadrada de chi cuadrado entre el número de casos.
Se fórmula es: ϕ=√χ2/n donde χ2 es el valor de la chi y n es igual al número de casos. Aunque en nuestro ejemplo no haría falta recurrir a phi ni a ningún otro estadístico, ya que la chi cuadrado nos mostró que no había relación de dependencia entre las variables, la hemos pedido con objeto de ilustrar el ejemplo. El valor de phi es de 0,079 lo que indica una relación muy baja. Además, el coeficiente de significación sigue alertando de que no hay relación de dependencia entre ambas variables.
-Coeficiente de contingencia: Es una prolongación de la phi para variables con más de dos categorías. Sin embargo, sus valores no están normalizados y su límite es menor que 1. Para conocer el límite máximo de C deberíamos calcularlo. Por ello, para ahorrar tiempo, se suele utilizar la V de cramer que sí está normalizada y tiene el límite máximo en 1, lo que indicaría una relación de dependencia perfecta. El coeficiente de contingencia se calcula como la raíz cuadrada de χ2 entre χ2 más el número de casos. C=√χ2/(χ2+n) Donde χ2 es el valor de chi cuadrado
-V de Crammer: Es quizás el estadístico más utilizado en las tablas de contingencia junto con Lamda. Su origen es similar al de Phi, aunque es válido para variables con más de dos categorías de respuesta. Toma valores entre 0 y 1. 1 indica máxima dependencia y 0 independencia. El valor de la V para tablas con alguna variable con dos categorías coincide con el valor de phi. La V de Cramer se obtiene ajustando phi para el número de filas o columnas de la tabla, cualquiera que sea el menor. V= ϕ2/min〖(r-1)(c-1)〗 Donde ϕ2 es el valor de phi, r es el número de filas y c el número de columnas. En nuestro ejemplo, la variable sexo tiene dos filas, por lo que el mínimo de (r-1)(c-1) = 2-1= 1. Elegimos la variable sexo que es la que menos categorías tiene y le restamos 1. La phi, por tanto, se divide por 1, motivo por el que la V de Cramer da el mismo resultado que la Phi cuando al menos una de las variables tiene solo dos categorías.
- Lambda: Estadístico utilizado para determinar si usar los resultados de una de las variables sirve para predecir los resultados de otra. Lambda toma valores entre 0 y 1, donde 0 indica independencia entre las variables y 1 total dependencia. Lambda igual a 1 implicaría que la variable independiente consigue reducir a 0 el error de la variable dependiente y digo implicaría porque es un caso extremo que no se suele dar. En nuestro ejemplo implicaría que conociendo la variable sexo podríamos averiguar que satisfacción tiene un sujeto cualquiera, algo poco probable incluso asumiendo un cierto grado de dependencia entre variables. Por defecto, SPSS nos saca tres valores de Lambda diferentes. Dos asimétricas cuando una de las variables puede ser considerada como dependiente y otra simétrica cuando no hay razón para pensar que hay una variable dependiente de la otra. Cómo calcular lambda
- Tau de Goodman Se parece a la Lambda aunque su cálculo es algo más complejo pues tiene en cuenta todas las categorías de respuesta y no únicamente la que más casos contempla. Al igual que Lambda adopta valores de 0 a 1, dónde 0 es independencia y 1 total dependencia. El valor de la Tau se interpreta como el porcentaje que mejora el error la inclusión de la variable independiente en la predicción de los valores de la variable dependiente. Por tanto, utilizar el sexo como variable independiente mejoraría la predicción de la satisfacción en un 1% un valor muy bajo y que sigue sin ser significativo estadísticamente. Cómo calcular la Tau de Goodman
Cuando nuestras dos variables son ordinales podemos elegir ciertos estadísticos que averiguan si conocer el orden de los casos en una variable resulta útil para predecir el orden de otra. Estos estadísticos toman valores entre -1 y 1. Donde 0 es independencia, -1 dependencia negativa perfecta (A mayor “x” menor “y” y viceversa), y 1 dependencia positiva perfecta. Entre estos estadísticos encontramos Gamma, Tau-b, Tau-c y D de Sommers. Tienen en común la consideración del ordenamiento de las categorías de las variables considerando todos los pares posibles en una tabla.
Gamma: La desventaja de este estadístico es que tiende a sobrestimar el grado de relación, por lo que es más común el uso de otros estadísticos para variables ordinales. Suele presentar valores mayores que las tau b y c. Su cálculo se realiza poniendo en relación los casos concordantes con los casos discordantes. Este estadístico no tiene en cuenta el número de casos empatados y tampoco hace correciones según el tamaño de la tabla. Cómo calcular Gamma .
Tau-b de Kendall: La Tau b de Kendall es parecida a Gamma, aunque tiene en cuenta el número de casos empatados. Toma valores entre -1 y 1, aunque no alcanza los valores extremos en tablas que no son cuadradas, es decir, en tablas con diferente número de filas que de columnas. Cómo calcular la Tau-b de Kendall.
Tau-c: : Es parecida a la Tau-b. Alcanza valores extremos en tablas que no son cuadradas, por lo que su uso es recomendable en tablas de tipo rectangular. Para ver su cálculo ir al enlace de la Tau-b.
D de Sommers: La D de Sommers es un estadístico similar a la Tau-b, aunque su fórmula varía ligeramente. Sus valores también oscilan entre -1 y 1. Presenta tres resultados diferentes: variable x como dependiente, variable y como dependiente y versión simétrica. Cómo calcular la D de Sommers A continuación vamos a ver un par de ejemplos del uso y la interpretación de una tabla de contingencia:


Echando un primer ojo a la tabla vemos que no hay una relación aparente entre las variables sexo e interés por el debate. En términos generales, hombres y mujeres parecen presentar porcentajes muy similares de interés. Por ejemplo, un 28,2% de los hombres creen que para la gente estos debates son bastante interesantes, porcentaje similar al de las mujeres con un 29,4%. Sin embargo, el nivel de significación de la chi cuadradado es de 0,00, lo que indica que estas dos variables se hayan relacionadas de algún modo. Ya hemos alertado que la chi cuadrado es muy sensible a determinados supuestos. Uno de ellos es que un elevado porcentaje de casillas con una frecuencia inferior a 5 imposibilita el uso de este estadístico. En este caso hay 2 casillas (un 16,7% del total) que tienen una frecuencia observada inferior a 5. Como la frecuencia observada difiere mucho de la frecuencia esperada, el estadístico se vuelve significativo a pesar de que no existe relación verdadera entre ambas variables. Por ende, todos aquellos estadísticos basados en la chi cuadrado indicarán cierto grado de relación entre las variables. Sin embargo, aquellos basados en el error parecen ser algo más resistentes a este efecto, por lo que si nos encontramos con un caso en el que hay muchas casillas con frecuencias pequeñas y no queremos recodificar las variables, lo más indicado será el uso de los estadísitcos basados en el error, como Lambda o la Tau de Goodman, aunque tampoco son inmunes, por lo que lo más apropiado es recodificar las variables si la lógica lo permite.





Un 74,3% de los hombres se interesa mucho o bastante por el deporte, mientras que entre las mujeres este porcentaje es de un 51,1%. Se puede apreciar, por tanto, cierto grado de relación entre ambas variables pero para asegurarnos debemos comprobar pidiendo los estadísticos correspondientes.


La relación entre ambas variables es fuerte ya que la V de Crammer tiene un valor de 0,271. En datos procedentes de encuestas es raro encontrar estadísticos con grados muy altos de relación. Normalmente a modo de norma no escrita en investigación social podemos considerar una relación fuerte cuando la V de Crammer es mayor que 0,240. Esta norma no es fija y como siempre además del estadístico que resume la información de la tabla es preferible examinar detalladamente la tabla.

Por el contrario, en los estadísticos basados en el error obtenemos menor fuerza de relación. Según el estadístico lambda conocer el interés por los deportes de una persona nos ayuda a reducir el error de la variable sexo en un 21,8% un porcentaje a tener en cuenta. Sin embargo, conocer el sexo no nos ayuda a conocer el interés, de hecho SPSS nos alerta de que no es posible dicho cálculo porque el error típico asintótico es igual a 0. Por tanto, nuestras dos variables se hayan relacionadas, aunque dicha relación no es suficiente para realizar buenas predicciones de una variable conociendo los valores de la otra.


Cálculo de chi cuadrado
Cálculo de lambda
Cálculo de tau de Goodman
Calculo de Gamma
Tau-b y c de Kendall
Cálculo D de Sommers
Cómo calcular una tabla de contingencia en SPSS
Interpretación Estadísticos
Ejemplos
Las tablas de contingencia son tablas que ponen en relación los datos de dos variables distintas. A través de un análisis de tabla de contiengencia podremos saber como se relacionan dos variables entre sí. Es uno de los análisis más sencillos y a la vez más utilizados en investigación social y de mercado.
1. Requisitos:
2. Cómo calcular una tabla de contingencia en SPSS:
Procedimiento: Una variable en la fila y otra variable en la columna. En el menú casilla pedimos el porcentaje por columna, además de la frecuencia de observados que sale en SPSS por defecto. Además, en el menú estadísticos pediremos la chi cuadrado. Con esto tenemos un primer análisis de tabla de contingencia.
3. Interpretación

4. Estadísticos
Chi cuadrado:
Estudia la relación entre las variables. Se selecciona en el menú estadístico de la tabla de contingencia. La hipótesis nula a contrastar es la independencia de las variables, siendo ladependencia la hipótesis alternativa.

Cosas a considerar de chi cuadrado:
La chi cuadrado está muy influenciada por el tamaño muestral. De modo que cuando tenemos muestras grandes la chi crece y es más fácil rechazar la hipótesis nula de independencia.
Para que el contraste de la chi sea estadísticamente válido cada celda de la tabla deberá tener una frecuencia esperada de 5. En nuestro ejemplo, como se ve en la línea de texto bajo la tabla de ejemplo no hay ninguna casilla que tenga menos de 5, por lo que nuestro test será estadísticamente válido. En el caso de que haya celdas con menos de 5 observaciones una posible solución es la recodificación de una variable con muchas categorías en una con menor número de categorías. Chi cuadrado puede funcionar con un porcentaje pequeño de celdas en las que se espere una frecuencia inferior a 5, pero con más de un 20% de las casillas con una frecuencia menor a 5 el test deja de ser fiable. Hasta ahora solo sabemos si existe o no dependencia entre las variables, pero no sabemos nada acerca del tipo de relación entre las variables . El siguiente grupo de estadísticos sirve para medir el grado de relación entre las variables.
Estadísticos para medir la fuerza de la relación:
En el menú estadísticos dentro de tabla de contingencia de SPSS es posible seleccionar varios estadísticos para medir la fuerza de la relación. Es importante saber si nuestras variables son nominales u ordinales, ya que según sea el tipo de variable elegiremos uno u otro estadístico. Cuando al menos una de nuestras variables es nominal debemos escoger los estadísticos para variables nominales. Si fueran las dos ordinales podríamos seleccionar estadísticos para variables ordinales que aportan mayor información.4.a Estadísticos para variables nominales:
Medidas que tienen que ver con el valor de Chi cuadrado:
La chi cuadrado nos avisa de si hay o no relación pero no nos habla muy bien de la fuerza de la relación, ya que su valor se haya relacionado con el tamaño muestral y no está acotado. Por ello, hay una serie de estadísticos basados en chi que corrigen este problema teniendo en cuenta el número casos.
Como se puede observar, los datos de los tres estadísticos coinciden en la tabla de nuestro ejemplo. Phi y Cramer siempre coinciden cuando al menos una de las variables tiene dos categorías de respuesta. El coeficiente de contingencia no es exactamente el mismo, aunque en este caso varía solo en el tercer decimal, que no sale por defecto en SPSS, por lo que coincide con los otros dos estadísticos. Veamos ahora estos estadísticos por separado: -Phi: Permite medir el grado de relación de dos variables. Se utiliza en el caso especial de tablas con dos filas y dos columnas (2x2). Valores cercanos a 0 indican poca relación y valores cercanos a 1 indican mucha fuerza en la relación. Se calcula como la raíz cuadrada de chi cuadrado entre el número de casos.
Se fórmula es: ϕ=√χ2/n donde χ2 es el valor de la chi y n es igual al número de casos. Aunque en nuestro ejemplo no haría falta recurrir a phi ni a ningún otro estadístico, ya que la chi cuadrado nos mostró que no había relación de dependencia entre las variables, la hemos pedido con objeto de ilustrar el ejemplo. El valor de phi es de 0,079 lo que indica una relación muy baja. Además, el coeficiente de significación sigue alertando de que no hay relación de dependencia entre ambas variables.
-Coeficiente de contingencia: Es una prolongación de la phi para variables con más de dos categorías. Sin embargo, sus valores no están normalizados y su límite es menor que 1. Para conocer el límite máximo de C deberíamos calcularlo. Por ello, para ahorrar tiempo, se suele utilizar la V de cramer que sí está normalizada y tiene el límite máximo en 1, lo que indicaría una relación de dependencia perfecta. El coeficiente de contingencia se calcula como la raíz cuadrada de χ2 entre χ2 más el número de casos. C=√χ2/(χ2+n) Donde χ2 es el valor de chi cuadrado
-V de Crammer: Es quizás el estadístico más utilizado en las tablas de contingencia junto con Lamda. Su origen es similar al de Phi, aunque es válido para variables con más de dos categorías de respuesta. Toma valores entre 0 y 1. 1 indica máxima dependencia y 0 independencia. El valor de la V para tablas con alguna variable con dos categorías coincide con el valor de phi. La V de Cramer se obtiene ajustando phi para el número de filas o columnas de la tabla, cualquiera que sea el menor. V= ϕ2/min〖(r-1)(c-1)〗 Donde ϕ2 es el valor de phi, r es el número de filas y c el número de columnas. En nuestro ejemplo, la variable sexo tiene dos filas, por lo que el mínimo de (r-1)(c-1) = 2-1= 1. Elegimos la variable sexo que es la que menos categorías tiene y le restamos 1. La phi, por tanto, se divide por 1, motivo por el que la V de Cramer da el mismo resultado que la Phi cuando al menos una de las variables tiene solo dos categorías.
Medidas basadas en el error proporcional
- Lambda: Estadístico utilizado para determinar si usar los resultados de una de las variables sirve para predecir los resultados de otra. Lambda toma valores entre 0 y 1, donde 0 indica independencia entre las variables y 1 total dependencia. Lambda igual a 1 implicaría que la variable independiente consigue reducir a 0 el error de la variable dependiente y digo implicaría porque es un caso extremo que no se suele dar. En nuestro ejemplo implicaría que conociendo la variable sexo podríamos averiguar que satisfacción tiene un sujeto cualquiera, algo poco probable incluso asumiendo un cierto grado de dependencia entre variables. Por defecto, SPSS nos saca tres valores de Lambda diferentes. Dos asimétricas cuando una de las variables puede ser considerada como dependiente y otra simétrica cuando no hay razón para pensar que hay una variable dependiente de la otra. Cómo calcular lambda
- Tau de Goodman Se parece a la Lambda aunque su cálculo es algo más complejo pues tiene en cuenta todas las categorías de respuesta y no únicamente la que más casos contempla. Al igual que Lambda adopta valores de 0 a 1, dónde 0 es independencia y 1 total dependencia. El valor de la Tau se interpreta como el porcentaje que mejora el error la inclusión de la variable independiente en la predicción de los valores de la variable dependiente. Por tanto, utilizar el sexo como variable independiente mejoraría la predicción de la satisfacción en un 1% un valor muy bajo y que sigue sin ser significativo estadísticamente. Cómo calcular la Tau de Goodman
4.b Medidas de asociación para variables ordinales:
Cuando nuestras dos variables son ordinales podemos elegir ciertos estadísticos que averiguan si conocer el orden de los casos en una variable resulta útil para predecir el orden de otra. Estos estadísticos toman valores entre -1 y 1. Donde 0 es independencia, -1 dependencia negativa perfecta (A mayor “x” menor “y” y viceversa), y 1 dependencia positiva perfecta. Entre estos estadísticos encontramos Gamma, Tau-b, Tau-c y D de Sommers. Tienen en común la consideración del ordenamiento de las categorías de las variables considerando todos los pares posibles en una tabla.
Gamma: La desventaja de este estadístico es que tiende a sobrestimar el grado de relación, por lo que es más común el uso de otros estadísticos para variables ordinales. Suele presentar valores mayores que las tau b y c. Su cálculo se realiza poniendo en relación los casos concordantes con los casos discordantes. Este estadístico no tiene en cuenta el número de casos empatados y tampoco hace correciones según el tamaño de la tabla. Cómo calcular Gamma .
Tau-b de Kendall: La Tau b de Kendall es parecida a Gamma, aunque tiene en cuenta el número de casos empatados. Toma valores entre -1 y 1, aunque no alcanza los valores extremos en tablas que no son cuadradas, es decir, en tablas con diferente número de filas que de columnas. Cómo calcular la Tau-b de Kendall.
Tau-c: : Es parecida a la Tau-b. Alcanza valores extremos en tablas que no son cuadradas, por lo que su uso es recomendable en tablas de tipo rectangular. Para ver su cálculo ir al enlace de la Tau-b.
D de Sommers: La D de Sommers es un estadístico similar a la Tau-b, aunque su fórmula varía ligeramente. Sus valores también oscilan entre -1 y 1. Presenta tres resultados diferentes: variable x como dependiente, variable y como dependiente y versión simétrica. Cómo calcular la D de Sommers A continuación vamos a ver un par de ejemplos del uso y la interpretación de una tabla de contingencia:
Ejemplos:
Ejemplo 1. Una variable nominal y otra ordinal
Vamos a ver un ejemplo en el que realizamos un análisis de contingencia con dos variables, una de tipo nominal y otra de tipo ordinal. Nuestro ejemplo va a estar basado en el estudio CIS 2980 sobre el último debate de la nación de febrero de 2013. Hemos seleccionado las variables P2 (interés de los debates) y P25 (sexo). Dentro del menú de SPSS análizar/estadísticos descriptivos/tablas de contingencia colocamos la variable sexo en la columna y en la fila la variable interés. En el menú casillas pediremos los porcentajes por columna, además de los observados que salen por defecto. En el menú estadísticos pediremos los estadíscos para variables nominales, ya que al menos una de nuestras variables es de tipo nominal. Pediremos, por tanto, chi, phi, V de Crammer, Coeficiente de contingencia, Lambda y la Tau de Goodman. Le damos a aceptar y obtenemos la siguiente salida en la hoja de resultados.

Echando un primer ojo a la tabla vemos que no hay una relación aparente entre las variables sexo e interés por el debate. En términos generales, hombres y mujeres parecen presentar porcentajes muy similares de interés. Por ejemplo, un 28,2% de los hombres creen que para la gente estos debates son bastante interesantes, porcentaje similar al de las mujeres con un 29,4%. Sin embargo, el nivel de significación de la chi cuadradado es de 0,00, lo que indica que estas dos variables se hayan relacionadas de algún modo. Ya hemos alertado que la chi cuadrado es muy sensible a determinados supuestos. Uno de ellos es que un elevado porcentaje de casillas con una frecuencia inferior a 5 imposibilita el uso de este estadístico. En este caso hay 2 casillas (un 16,7% del total) que tienen una frecuencia observada inferior a 5. Como la frecuencia observada difiere mucho de la frecuencia esperada, el estadístico se vuelve significativo a pesar de que no existe relación verdadera entre ambas variables. Por ende, todos aquellos estadísticos basados en la chi cuadrado indicarán cierto grado de relación entre las variables. Sin embargo, aquellos basados en el error parecen ser algo más resistentes a este efecto, por lo que si nos encontramos con un caso en el que hay muchas casillas con frecuencias pequeñas y no queremos recodificar las variables, lo más indicado será el uso de los estadísitcos basados en el error, como Lambda o la Tau de Goodman, aunque tampoco son inmunes, por lo que lo más apropiado es recodificar las variables si la lógica lo permite.


En este caso, el problema es de fácil solución, ya que solo tenemos que eliminar del análisis los casos que no supieron o no que quisieron contestar a esta pregunta. De ahí la importancia de depurar bien la base de datos y de eliminar valores perdidos en los análisis a no ser de que pretendamos buscar una relación causal que motive esa no respuesta.
A continuación volvemos a realizar el análisis pero dejando fuera los casos no sabe y no contesta.

Cómo se puede observar ahora el nivel de siginificación es de 0,227, por tanto, mayor que 0,05. Por ello, no podemos rechazar la hipótesis inicial y decimos que las variables sexo e interés no están relacionadas entre sí. El resto de estadísticos basados en la chi cuadrado ahora tampoco son significativos y su valor ha bajado considerablemente hasta 0,053.

Ejemplo 2. Una variable nominal y otra ordinal
Vamos a ver otro ejemplo parecido pero con variables que guardan cierta relación entre ellas para ver cómo se comportan nuestros estadísticos: La base de datos que vamos a usar es el estudio 2833 del CIS sobre hábitos deportivos en 2010. Las variables que vamos a usar son P1 (interés por los deportes) y la P65 (sexo).
Un 74,3% de los hombres se interesa mucho o bastante por el deporte, mientras que entre las mujeres este porcentaje es de un 51,1%. Se puede apreciar, por tanto, cierto grado de relación entre ambas variables pero para asegurarnos debemos comprobar pidiendo los estadísticos correspondientes.

Como vemos en este estudio hay muchos casos (n= 8.909) por lo que la chi cuadrado saldrá muy alta y probablemente significativa. Es necesario pedir los estadísticos basados en chi cuadrado que como hemos visto tienen en cuenta el número de casos.

La relación entre ambas variables es fuerte ya que la V de Crammer tiene un valor de 0,271. En datos procedentes de encuestas es raro encontrar estadísticos con grados muy altos de relación. Normalmente a modo de norma no escrita en investigación social podemos considerar una relación fuerte cuando la V de Crammer es mayor que 0,240. Esta norma no es fija y como siempre además del estadístico que resume la información de la tabla es preferible examinar detalladamente la tabla.

Por el contrario, en los estadísticos basados en el error obtenemos menor fuerza de relación. Según el estadístico lambda conocer el interés por los deportes de una persona nos ayuda a reducir el error de la variable sexo en un 21,8% un porcentaje a tener en cuenta. Sin embargo, conocer el sexo no nos ayuda a conocer el interés, de hecho SPSS nos alerta de que no es posible dicho cálculo porque el error típico asintótico es igual a 0. Por tanto, nuestras dos variables se hayan relacionadas, aunque dicha relación no es suficiente para realizar buenas predicciones de una variable conociendo los valores de la otra.
Ejemplo 3. Dos variables ordinales
Por último, vamos a ver un ejemplo en el que ponemos en relación dos variables de tipo ordinal. El estudio que vamos a utilizar es el mismo del ejemplo anterior 2833 del CIS sobre hábitos deportivos. Hemos elegido las variables edad e interés por los deportes. Como en el caso anterior hemos eliminado del análisis los casos perdidos. La variable continua edad la hemos recodificado en una variable ordinal según intervalos óptimos a la variable interés deporte para que presente las mayores diferencias posibles entre estas dos variables. Antes de nada, hemos de comprobar cómo están ordenadas las categorías de nuestras variables. La variable P1 (interés deporte) está ordenada de menor a mayor, mientras que la variable edad está codificada de mayor a menor. A fin de facilitar el análisis es aconsejable hacer que nuestras variables presenten un mismo tipo de ordenación. Para ello, recodificamos P.1 en orden inverso.

Los estadísticos para variables ordinales muestran una ligera relación de carácter negativo. A mayor edad, menor interés por el deporte y viceversa. En la tabla de contingencia podemos ver que un 30% de los menores de 27 están muy interesados por el deporte, mientras que este porcentaje va disminuyendo progresivamente hasta los mayores de 72 con un 12,4%. Las categorías mucho y nada interrelacionan muy bien con la edad, sin embargo las categorías bastante y poco presentan porcentajes similares para todas las edades, por lo que lo estadísticos no muestran una relación muy pronunciada. Aún así queda patente el mayor interés de los más jóvenes por los deportes. La significación aproximada es menor que 0,5, por lo que dicha relación puede ser extrapolada al conjunto de la población. Es decir, las diferencias observadas en nuestra muestra son extrapolables al conjunto de la población, en este caso los españoles.
Artículos relacionados en este blog
Suscribirse a:
Entradas (Atom)